是 強化學習 (Reinforcement Learning, RL) 中一種經典演算法。它讓 智能體(agent) 能夠透過與環境互動,學習到在不同狀態下採取何種行動,以獲得最大的長期累積獎勵
狀態(State):智能體當下所處的環境情況行動(Action):智能體可採取的各種動作獎勵(Reward):智能體執行某個動作後所獲得的回饋,可能是正的或負的Q 值(Q-value):代表在某個狀態下採取某個行動所預期的累積未來獎勵Q 表(Q-table):用來儲存所有狀態-行動對應的 Q 值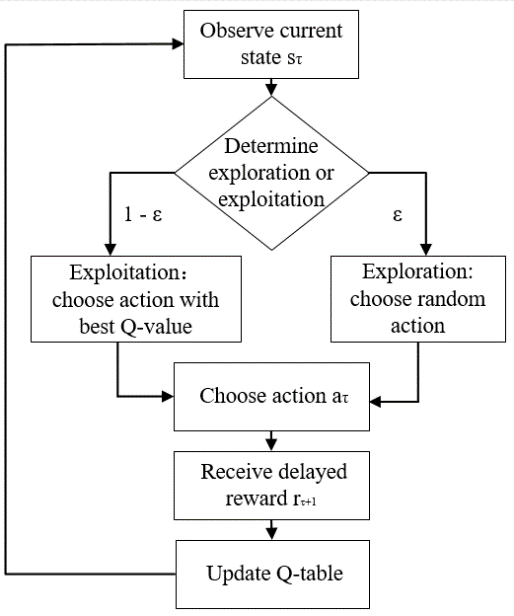
圖片來源:(https://www.researchgate.net/figure/Q-learning-algorithm-flowchart_fig1_334244533)
初始化 Q 表:將 Q 表中的所有值初始化為隨機值選擇行動:根據當前的狀態,選擇一個行動ε-貪婪法:以 ε 的機率隨機選擇行動,以 1-ε 的機率選擇 Q 值最大的行動執行行動:智能體執行所選擇的行動,並觀察得到的獎勵和新的狀態根據 Bellman 方程更新 Q 值
Q(s, a) <- Q(s, a) + α[r + γ * max(Q(s', a')) - Q(s, a)]
s |
當前狀態 |
|---|---|
a |
當前行動 |
α |
學習率 |
r |
得到的獎勵 |
γ |
折扣因子 |
s' |
新的狀態 |
a' |
新的狀態下可能採取的所有行動 |
重複步驟 2-4,直到 Q 表收斂或達到指定的學習次數
圖片來源:(https://www.researchgate.net/figure/Q-learning-algorithm-pseudo-code_fig1_345263898)
優點:概念簡單、適用性廣、無需環境模型缺點:維度災難(當狀態和行動空間很大時,Q 表的維度會變得非常大)、僅適用於離散的狀態和行動空間遊戲AI:Atari 遊戲、圍棋機器人控制:機器人行走、抓取物體推薦系統:根據用戶的歷史行為推薦商品金融交易:根據市場數據進行股票交易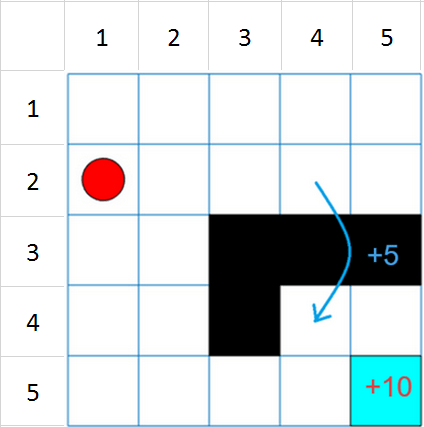
import numpy as np
# 初始化 Q 表
q_table = np.zeros((num_states, num_actions))
# 更新 Q 值
def update_q_value(state, action, reward, next_state, alpha, gamma):
q_table[state, action] = q_table[state, action] + alpha * (reward + gamma * np.max(q_table[next_state, :]) - q_table[state, action])
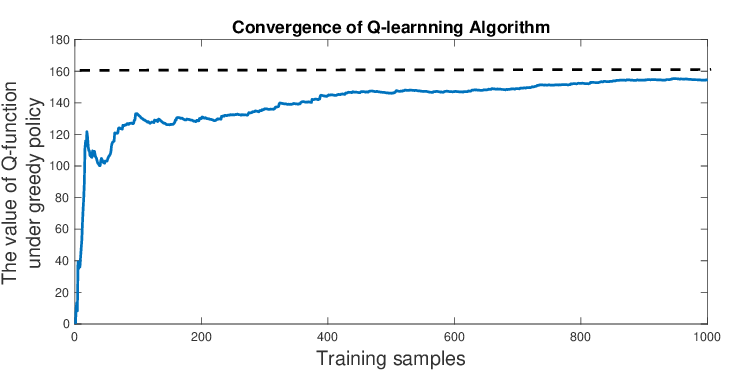
Q-learning 作為強化學習的基礎演算法,為我們提供一個簡單而有效的方式,讓智能體能夠從與環境的互動中學習。雖然 Q-learning 有其局限性,但它為後續更複雜的強化學習演算法奠定基礎


 iThome鐵人賽
iThome鐵人賽